Sobre este Apache Spark Tutorial
Apache faísca
Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing. This is a brief tutorial that explains the basics of Spark Core programming.
This tutorial has been prepared for professionals aspiring to learn the basics of Big Data Analytics using Spark Framework and become a Spark Developer. In addition, it would be useful for Analytics Professionals and ETL developers as well.
Before you start proceeding with this tutorial, we assume that you have prior exposure to Scala programming, database concepts, and any of the Linux operating system flavors.
Informações Adicionais do Aplicativo
Última versão
1.5Enviado por
Nong'san Prungtang
Requer Android
Android 4.0+
Categoria
Grátis Livros e referências APPClassificação do Conteúdo
Everyone
Relatório
Marcar como inapropriadoNovidades da Última Versão 1.5
Last updated on May 17, 2018
Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types of computations which includes Interactive Queries and Stream Processing. This is a brief tutorial that explains the basics of Spark Core programming.
Apache Spark Tutorial Capturas de tela

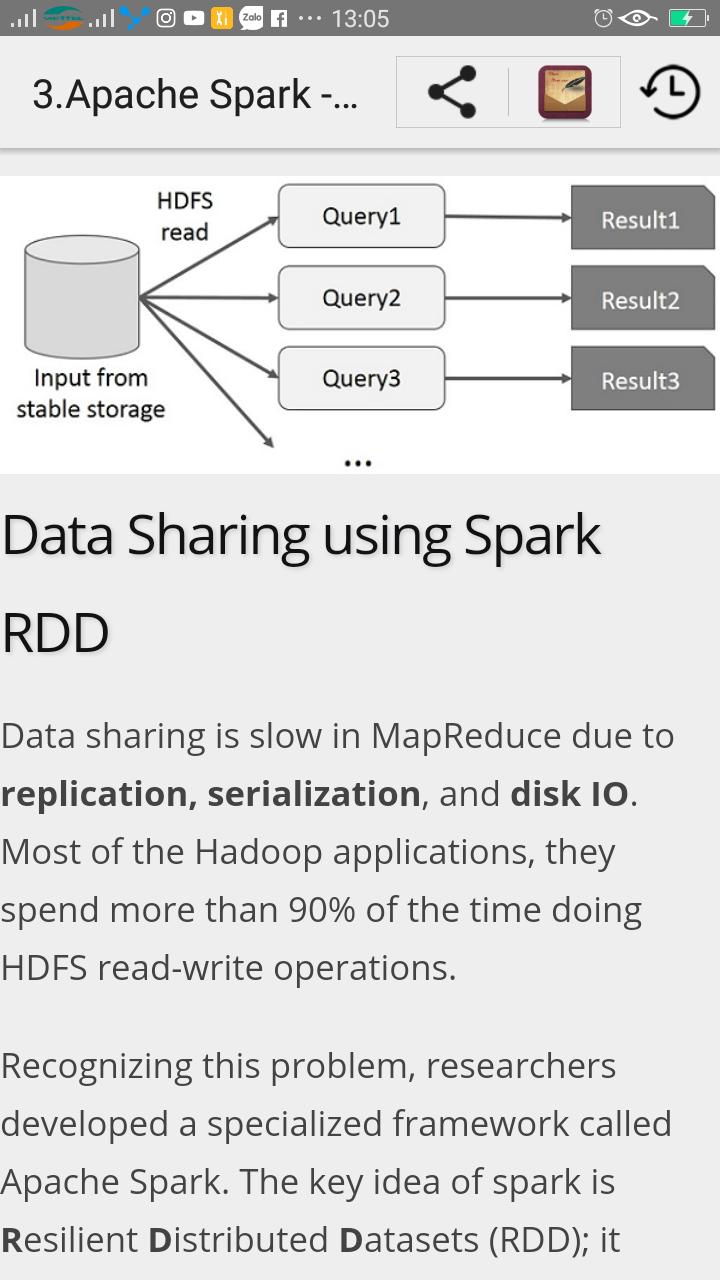
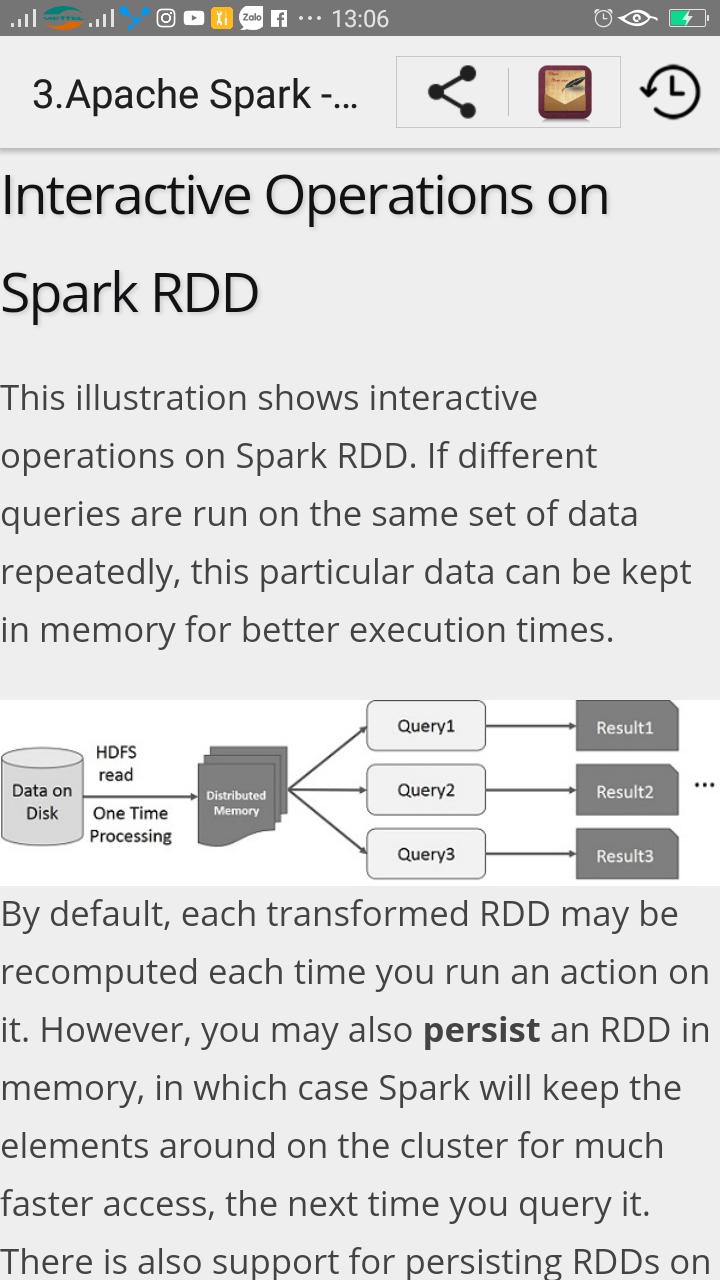


Versões Antigas de Apache Spark Tutorial
Todas as Versões
Tags Relacionadas
Artigos Populares nas Últimas 24 Horas
- Como baixar Teste do Minecraft apk versão mais recente 1.26.33.1 para Android 2026
- Como baixar Toca Boca World apk versão mais recente 1.135 para Android 2026
- Códigos do EA SPORTS FC MOBILE 26 (Julho de 2026) para resgatar recompensas gratuitas
- Como baixar Pobreflix apk versão mais recente 2.20 para Android 2026




